Data Mining Notes
Introduction:
•Data mining is the task of discovering interesting patterns from large amounts of data, where the data can be stored in databases, data ware houses, or other information repositories.
•Data mining is often defined as finding hidden information in a database.
•Data mining involves an integration of techniques from multiple disciplines such as database and data warehouse technology, statistics, machine learning, high-performance computing, pattern recognition, neural networks, data visualization, information retrieval, image and signal processing, and spatial or temporal data analysis.
DATA MINING MODEL & TASK
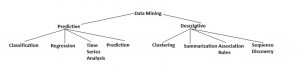
1. Classification:
•Classification maps data into predefined groups or classes.
•It is often referred to as supervised learning because the classes are determined before examining the data.
•Two examples of classification applications are determining whether to make a bank loan and identifying credit risks.
•Pattern recognition is a type of classification where an input pattern is classified into one of several classes based on its similarity to these predefined classes.
2.Regression
•Regression is used to map a data item to a real valued prediction variable.
•Regression assumes that the target data fit into some known type of function (e.g. linear, logistic etc) and then determines the best function of this type that models the given data.
•For example, a college professor wishes to reach a certain level of savings before his retirement. Periodically, he predicts what his retirement savings will be based on its current value and several past values. He uses a simple linear regression formula to predict this value by fitting past behavior to a linear function and then using this function to predict the values at points in the future. Based on these values, he then alters his investment portfolio.
3.Time Sereis Analysis:
•With time series analysis, the value of an attribute is examined as it varies over time.
•A time series plot is used to visualize the time series. In this figure, you can easily see that the plots for Y and Z have similar behavior, while X appears to have less volatility.
•There are three basic functions performed in time series analysis. In one case, distance measures are used to determine the similarity between different time series. In the second case, the structure of the line is examined to determine (and perhaps classify) its behavior. A third application would be to use the historical time series plot to predict future values.
4 Prediction:
•Many real-world data mining applications can be seen as predicting future data states based on past and current data. Prediction can be viewed as a type of classification.
•The difference is that prediction is predicting a future state rather than a current state. Here reference is made to a type of application rather than to a type of data mining approach. Prediction applications include flooding, speech recognition, machine learning and pattern recognition. Although future values may be predicted using time series analysis or regression techniques, other approaches may be use as well.
5 Clustering:
•Clustering is similar to classification except that the groups are into predefined, but rather defined by the data alone.
•Clustering is alternatively referred to as unsupervised learning or segmentation.
•It can be thought of as partitioning or segmenting the data into groups that might or might not be disjointed. The clustering is usually accomplished by determining the similarity among the data on predefined attributes. The most similar data are grouped into clusters.
•A special type of clustering is called segmentation. With segmentation a database is partitioned into disjointed groupings of similar tuples called segments. Segmentation is often viewed as being identical to clustering. In other circles segmentation is viewed as a specific type of clustering applied to a database itself.
6 Summerization Association Rules:
•Summarization maps data into subsets with associated simple descriptions. Summarization is also called characterization or generalization.
•It extracts or derives representative information about the database. This may be accomplished by actually retrieving portions of the data. Alternatively, summary type information can be derived from the data. The summarization succinctly characterizes the contents of the database.
•Link analysis, alternatively referred to as affinity analysis or association, refers to the data mining task of uncovering relationships among data.
•The best example of this type of application is to determine association rules. An association rule is a model that identifies specific types of data associations. These associations are often used in the retail sales community to identify items that are frequently purchased together.